Running Splunk Infrastructure in AWS
In my earlier post, I wrote about running Splunk infrastructure in Google Cloud. The challenge of having to replicate it in AWS was too good to resist. In this post I’ll tackle how Splunk architecture can be be implemented using a IaaS solution.
On Premise Architecture
The general architecture of Splunk when running from on-premise consists of following resources and artifacts that are used -
- Indexer Cluster storing and indexing the data.
- Search Heads to query the data.
- Indexer Master to manage the licensing.
- Heavy Forwarders to manage the data flow from the Forwarders.
So the architecture would look something like this-
For the brevity of this solution I’ve kept the storage perspective of of this post.
AWS Infrastructure
Transporting the architecture to AWS it would look something like this -
I’ve spread the architecture over 2 Zones to provide some redundancy and this could be spread over 2 Regions to provide even more redundancy. The Splunk infrastructure is being run from a Private Subnet to avoid public access. A jump host in the public subnet provides the access to the Splunk Instances in Private Subnet. I’ve used the jump host to transfer the Splunk software that will be installed on the Indexers, Index Master, Search Heads and Heavy Forwarders. All of the instances are of the same configuration t3.medium running Ubuntu with 30GB of EBS storage added to them. For simplicity, I’ve had the Search Head and Index Master run from the us-east-2a zone.
I’ve utilized the default NACL in this and the Security Groups associated with the Splunk instances have the following ports allowed — SSH(22), Splunk Replication(9887), Port for Indexing Receive and Forward on Heavy Forwarder(9997) and Web admin access for Index Master and Search Head(8000 and 8089).
The Index Master being in Private Subnet I’ve exposed it using a ALB(Application Load Balancer) via port 8000. The Heavy Forwarders are exposed from the same ALB via port 8001 for east-2a and 8002 for east-2b.
Configure Splunk Servers
Configuring the Splunk Servers requires the configuration file to have the same password as it is required for Indexer clustering. After the splunk instance has been started the password will be hashed. Below is the screenshot of the servers that have been configured and created in different zones.

To expose the Index Master and Heavy Forwaders via ALB, I’ve created an individual Target Groups(TGs). These Splunk services are exposed on the same port i.e. 8000.
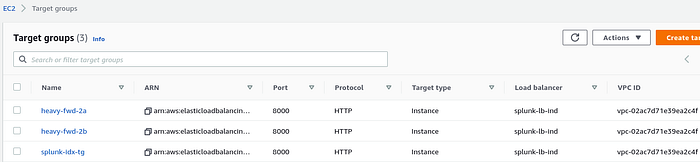
A single ALB exposes 3 different TGs, the ALB is configured to utilize 3 different ports. The Index Master is being exposed using port 8000, the SH1 on 8001 and SH2 on port 8002.
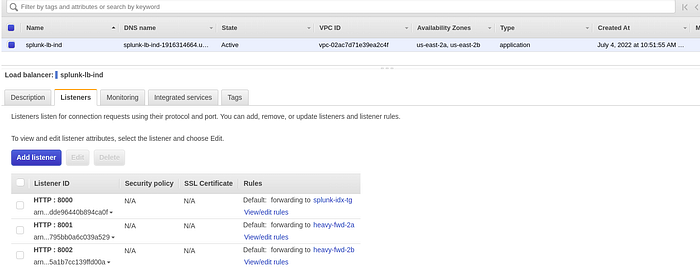
The ALB should have a unique DNS name on creation associated with it that can used to access Splunk Servers. Since much of the configuration is done in via the server.conf file in the servers, once the Index Master starts up, the servers should show up in the Index clustering view. Please note that for the Splunk Servers I’ve used private IP addresses to configure them in the server.conf as these IP address are not changed on restart.
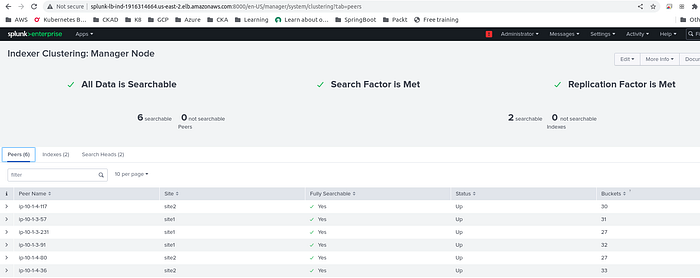
The Index Master will show up the following IP address in the Index Clustering panel.
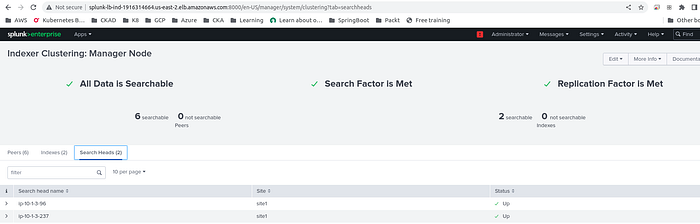
The Search Head tab will show the Search Head Server.
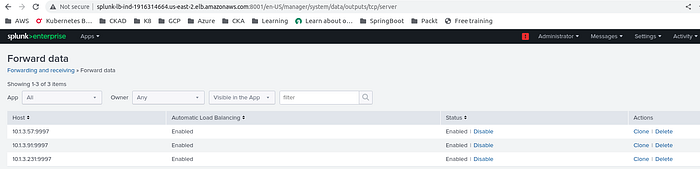
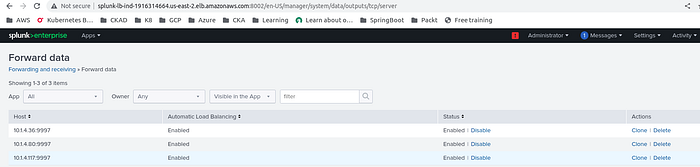
The Heavy Forwarders have been configured with the receiving and forwarding ports in addition to that, the Indexers have been configured with the Heavy Forwarders in respective zones to transfer the data.
Heavy Forwarder east-2a
Heavy Forwarder east-2b
Summary
To summarize the solution, EC2 instances are utilized as Indexers as part of Index cluster, Search Heads and Heavy Forwarders. For the storage EBS clocks can be utilized and as required they can be added. The actual setup may not use an Internet Gateway and the log and events from Universal Forwarders will be internal and not using Internet.
